Notice how the co-ordinates are returned as an array of two strings where each string contains a decimal degrees value.
It’s clear what the data means, but for Amazon QuickSight to plot it on a map, it needs to have this coordinate expressed in the correct type – in this case a Geo coordinate.
As I mentioned before, we can use a QuickSight calculated field to solve this problem. This time the formula we need is a little more complex but in essence we are going to split the string into 2 and use one part for a Latitude Geo Coordinate and the other for a Longitude Geo Coordinate.
Here’s the calculated field formula for the Latitude
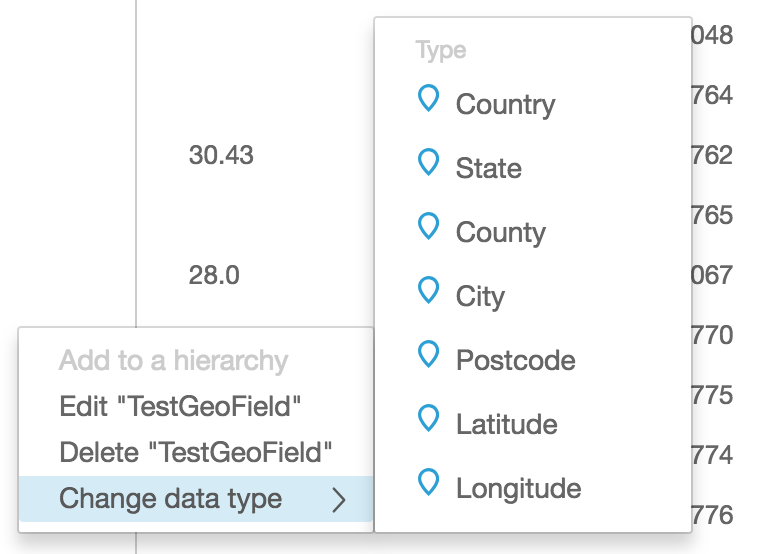
These calculated fields will be numbers to start with, we still need to tell QuickSight that we want to treat these as coordinates suitable for mapping, so use the edit data type feature to convert them to the appropriate Geo type like this.
Once you have Latitude and Longitude fields, you’ll be able to visualise them on the map charts built in to QuickSight.
IoT devices send a wide range of message shapes and sizes, and for my own experiments, I typically send a different type of message for each sensor. So for example;
I have maybe 20-30 different messages in my small home automation setup and I’d like the freedom to be able to create new message formats without having to worry about how to store all this data for later analysis, so one of the first questions that arises is where should I store all this data?
A natural destination for any IOT device data is the new IoT Analytics service that was launched by AWS back in April at the world’s largest industrial technology trade fair “Hannover Messe”. IoT Analytics has several features that make the collection and later analysis of connected device data easy;
Flexible retention periods. Keep all your data for a week, a month or any period that you require, including of course unlimited retention. Aside from helping reduce costs by automatically removing old and non longer needed data, this also helps keep query performance higher by lowering the overall amount of data being scanned.
Zero schema configuration required. You don’t need to specify any partition keys or column names or tell IoT Analytics anything about your message schema. Just send the data and it will be stored and made available for query. I like this because it makes it super easy to get up and running.
Preprocess message data before storage. IoT Analytics has a Pipeline that connects the incoming messages from a Channel to the Datastore – your data lake of connected device data. This gives me a data preparation step where I can enrich or transform the message according to my requirements. For example I might want to enrich the message with data from the IoT device shadow or add information from the IoT device registry. I might want to convert a measurement in fahrenheit to celcius or even call out to an external service to get some additional data about the device to add to the message. There are some pretty cool things you can do with the data preparation stage and I’ll write more about those another time.
Ability to write standard SQL queries against your data. I call this out in particular because prior to the release of AWS IoT Analytics, I was using AWS ElasticSearch as my data repository. This had similar ease of use characteristics regarding schema configuration (not quite zero touch, but not particularly onerous either) and was certainly useful for visual analysis and deep diving with Kibana, but ES has it’s own query language based on Lucene and this makes decades of familiarity with SQL obsolete and having to learn how to query from the beginning was a learning curve that I sometimes found frustrating.
Recurring scheduled queries. One of my use cases concerns looking at historic and future weather data to determine when to turn on an irrigation system and for how long. I want to execute this analysis every evening to configure the watering for the next day – a perfect fit for a scheduled query that runs every day. Another use case I have is that of analysing upper atmosphere clarity to see if my telescope should continue to execute its observing program – a great fit for analysis that is scheduled to run every 15 minutes.
I love being able to automate my analysis like this without having to write a single line of code. This definitely makes my life easier when I’m wearing my data scientist hat.
And, saving the best for last …
Automated execution of Jupyter Notebooks for fully hands-off analysis workloads. For me, this is the real engine within IoT Analytics that makes it so flexible and capable. Not only can I use the notebook to perform deeper statistical analysis or train an ML scenario, or draw complex graphs and charts, but because I have the full power of the AWS SDK at my fingertips, I can do anything you can think of doing with all the tools that puts at your disposal. One simple use case I solve with this approach is to configure AWS CloudWatch Event Rules to schedule when water should be turned on and off and I’ll write more about this in some detail another time.
Example Jupyter Notebook fragment
In conclusion, the ease of sending any data in, the ability to query the data on an automated schedule and the power of the analysis available has enabled me to focus more on the business problems I’m trying to solve. For every new project I’m dreaming up (I’m an inveterate tinkerer remember), I just create a new IoT Analytics Channel->Pipeline->Datastore and that becomes the home for all the device data I’m sending.
It’s not uncommon for IoT Devices to send timestamp information in simple integers like a unix timestamp or epoch. For example, the time of 10/08/2018 @ 1:05am (UTC) is represented by the epoch 1538960714 which is the number of seconds since Jan 1st 1970. Sometimes we might also have this in milliseconds, such as when we use an IoT Core Rule to add a timestamp to the incoming message.
If I have an AWS IoT Analytics Data Set containing epoch seconds or milliseconds, I’ll find it difficult to use that data effectively in Amazon QuickSight which really needs to have a date type column in order to consider it as a time. What to do?
This is where QuickSight’s ability to have calculated fields comes to the rescue.
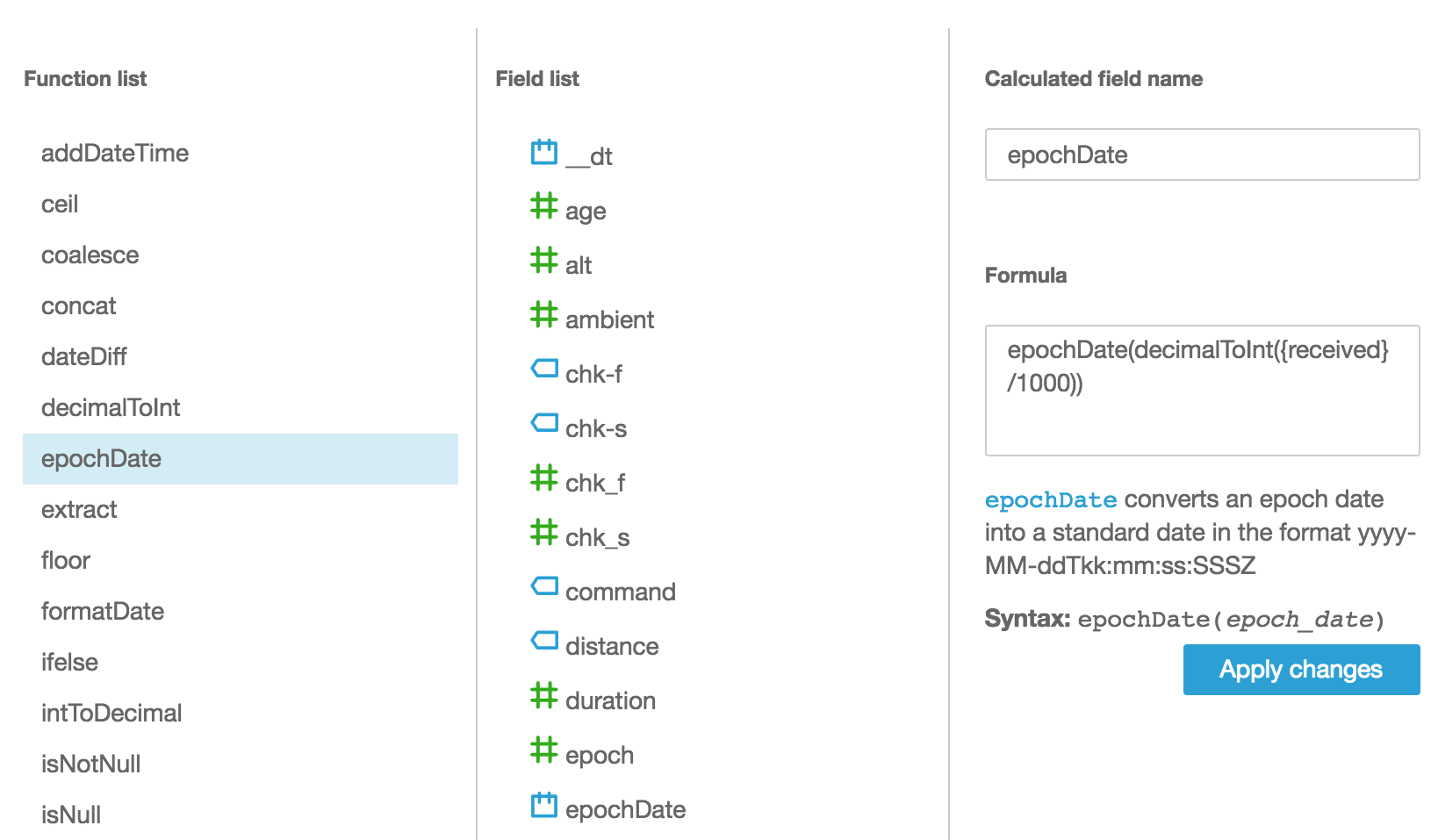
Click on New field and then give your new field a name such as epochDate. Then you want to use the epochDate built in function to convert your epoch seconds or milliseconds data into the right format.
In this example my messages contain a field called received which is in epoch milliseconds, and so I’m dividing that by 1000, converting the result to an integer (required by the epochDate function) and then returning the result of the epochDate() function.
When you create a Data Set with IoT Analytics, the default SQL query that is shown in the SQL editor is something like this;
SELECT * FROM datastore
Whilst there’s nothing wrong with this as a starting point, it’s important to realise that an unconstrained query like this will do a full table scan of your data every time it is executed. That may be OK if you have a short retention period configured for your datastore and you only have a few thousand messages, but imagine having terabytes of data stretching back over years and really you only want to get data for the last few days? The query above may work (it may also time out), but it’s vastly inefficient and you’ll be paying for the privilege of scanning the entire data store every time.
There is a better way.
Your first starting point should always be to use a WHERE clause referencing the system provided __dt column. For ‘dt’, think ‘datetime’ because it is this column that gives you access to the time based partitions that help you make queries on IoT Analytics and the double underscores are used to avoid clashes with any attribute names in your own data.
Here’s an example that just looks at data from the past day.
select * from telescope_data where __dt >= current_date - interval '1' day
__dt has a granularity of 1 day so if you want to look at a narrower time-range, you would add a constraint on whatever timestamp column you had in your data, but always, always, always include the __dt constraint as part of your where clause to maximise query performance and lower query cost.
For example, what if we just want data from the last 15 minutes in our query results?
select * from telescope_data where __dt >= current_date - interval '1' day
and from_unixtime(epoch) > now() - interval '15' minute
Notice that we have the __dt clause to restrict data to the most recent day and then have a clause based on the epoch reported in each message to further restrict to the last 15 minutes.
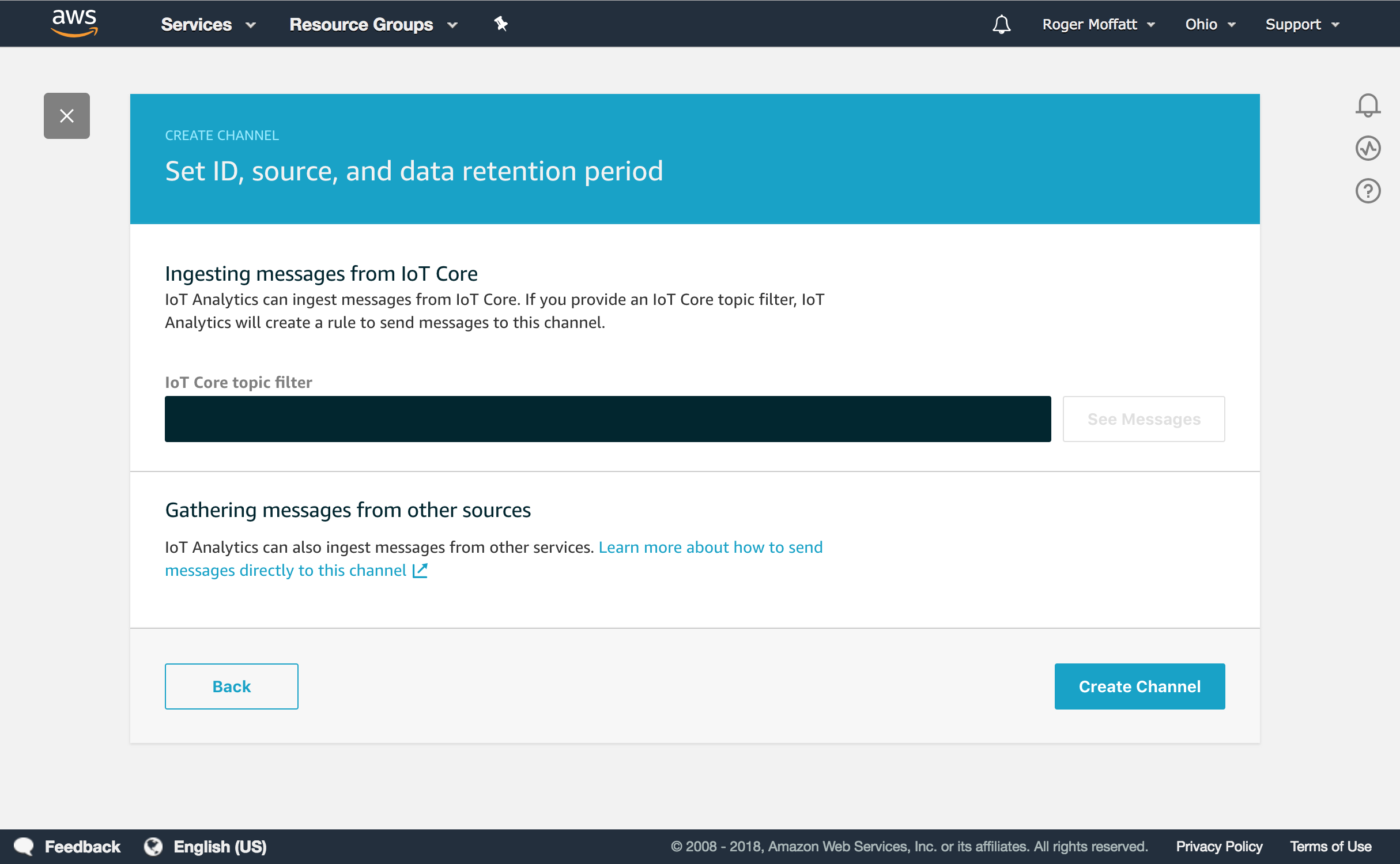
The Create Channel workflow in the IoT Analytics Channel encourages you to specify an MQTT Topic Filter to listen for messages – but did you realise this is completely optional?
Just click directly on the Create Channel button without entering anything on this page and the Rule won’t be created for you. You can choose to setup a Rule later in the IoT Core Console or if you are not using MQTT at all, you can simply send your data to the Channel using the batch-put-message API from the programming language of your choice.
Last time we looked at how to create your first channel to receive data from your connected IoT device. This week we’re going to take a closer look at the IoT Core Rule that was created for you last time and then go on to create the Pipeline that will connect this Channel to a Data store where all your data will be available for query.
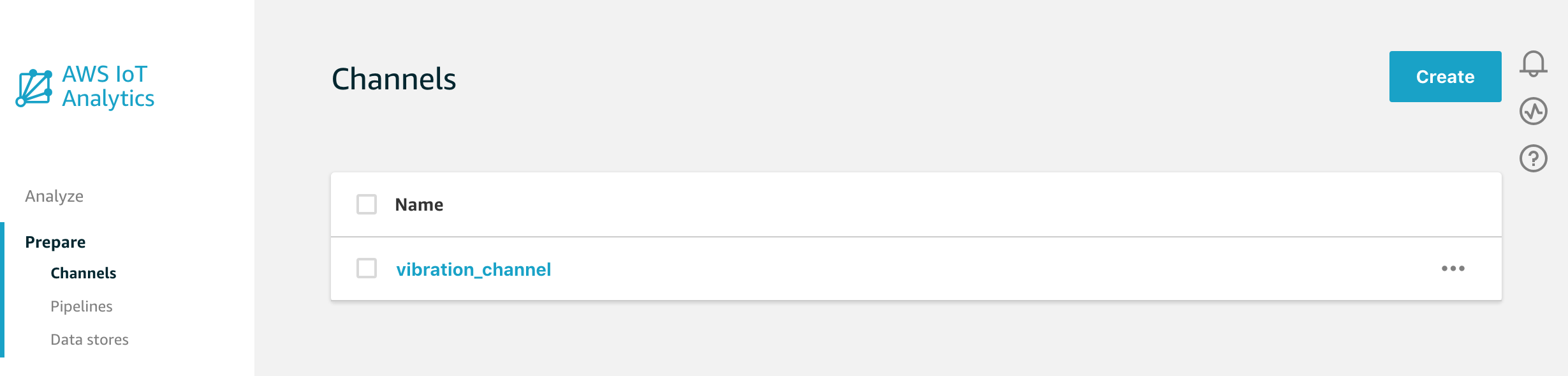
First though, let’s remind ourselves which Channel we’re going to be working with today by visiting the Channels page in the IoT Analytics Console.
We’ll be using this vibration_channel to collect data from our vibration sensor project.
Last week I mentioned that using the topic filter in the Channel creation flow would automatically create a Rule for you in IoT Core, so let’s mosey on over to the IoT Core Console, select Act from the menu on the left and take a look at what rules we now have.
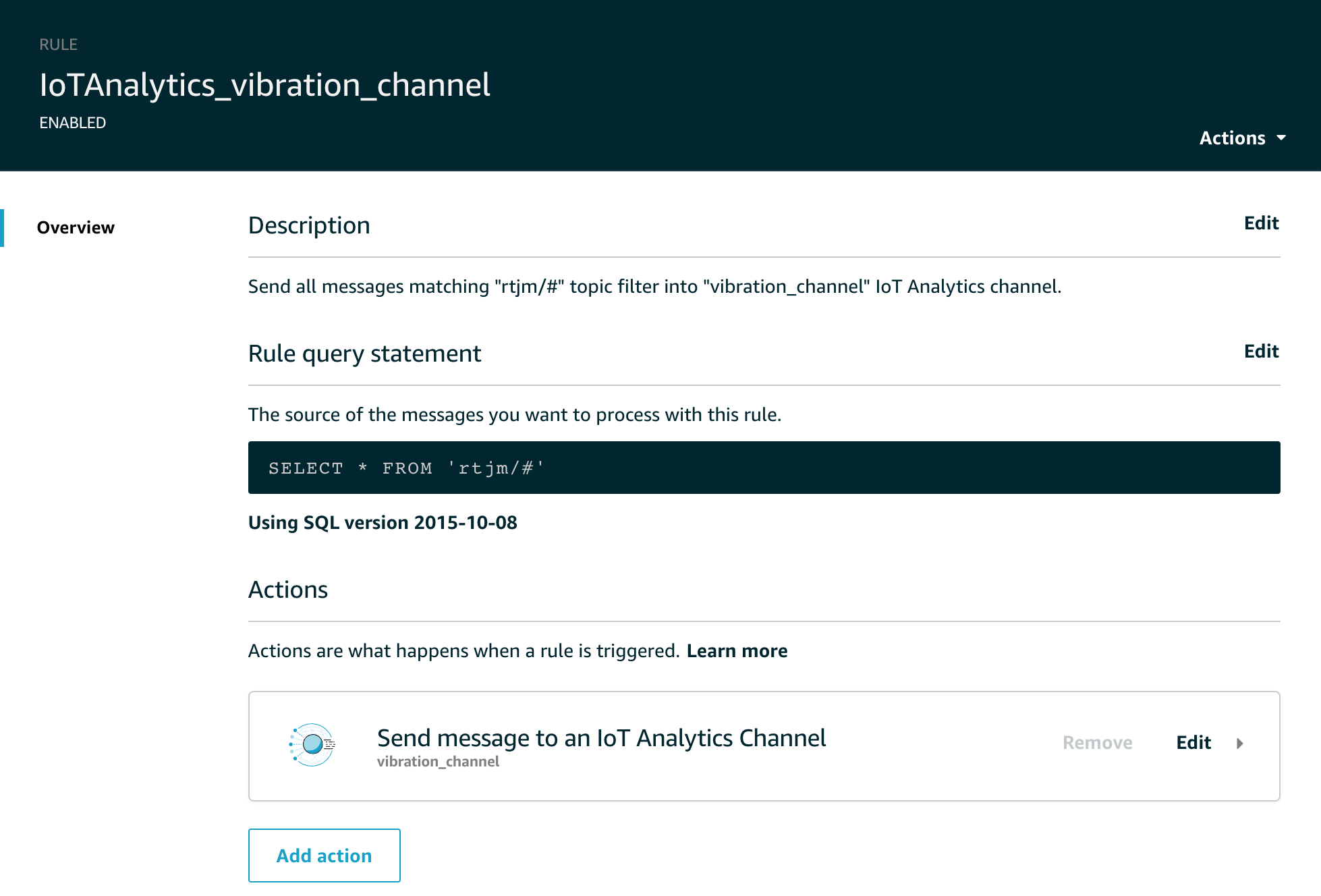
Cool – we have a rule called IoTAnalytics_vibration_channel. Note now any rules created automatically like this are prefixed by the IoTAnalytics keyword to make them easier to locate. Let’s click on that and take a look at the rule in some more detail.
As you can see, for this rule we are taking all messages from the wildcard topic filter rtjm/# and sending them to the vibration_channel using the IoT Analytics Channel. We can use this screen to edit the topic filter, edit the action or add another action. This last point is worth remembering, you may want to send messages to multiple destinations and adding multiple actions in the Rule is one of the ways of doing this.
For now, let’s head back to the IoT Analytics Channel and create the Pipeline to join everything together.
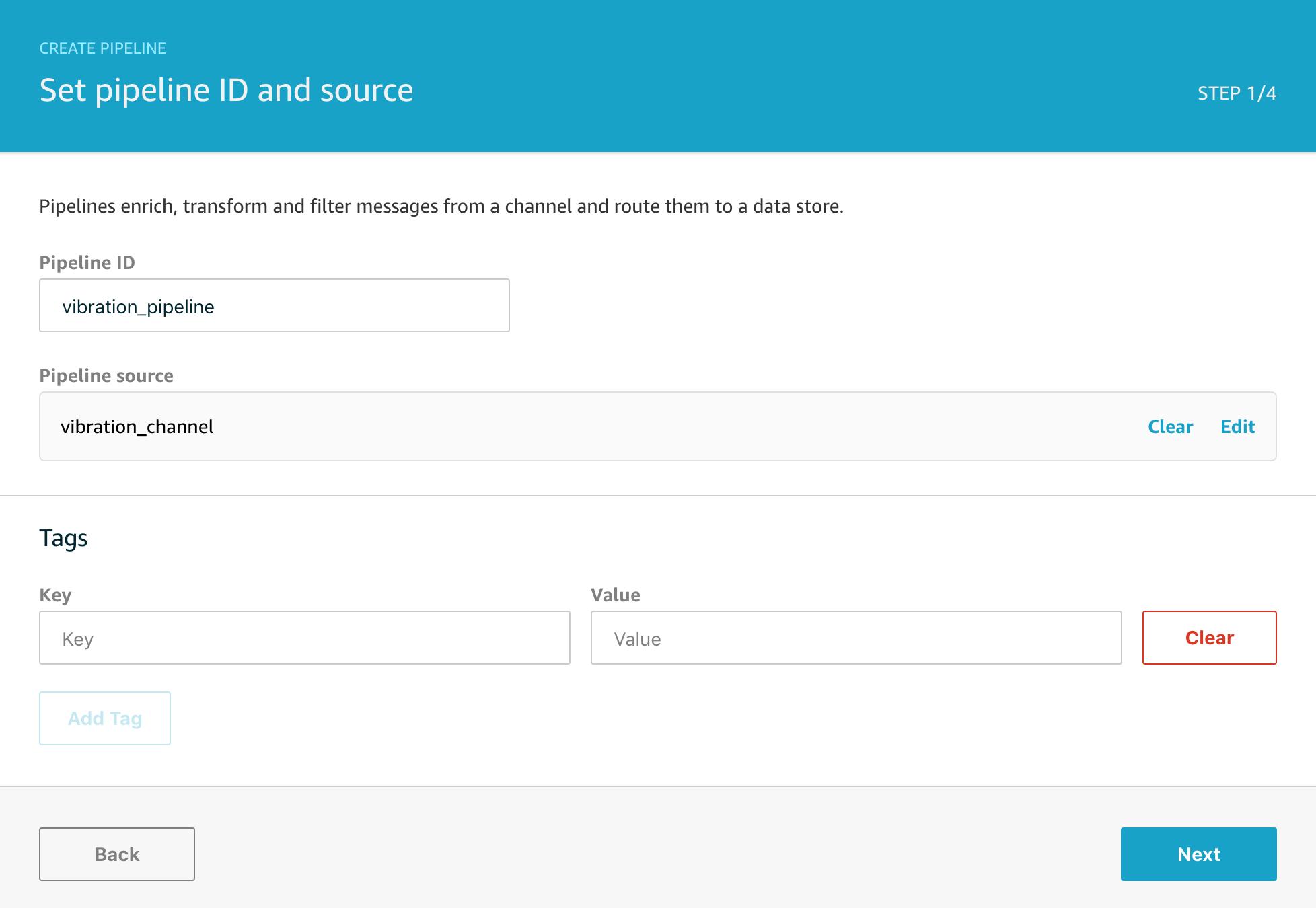
STEP ONE
We’ll start by naming the Pipeline and selecting the Channel we created time as the source. Every Pipeline needs to get its data from somewhere and so the first mandatory step is to connect the Pipeline to the message source.
Again, you can choose to optionally tag your resources, but for now we’ll just click through with Next.
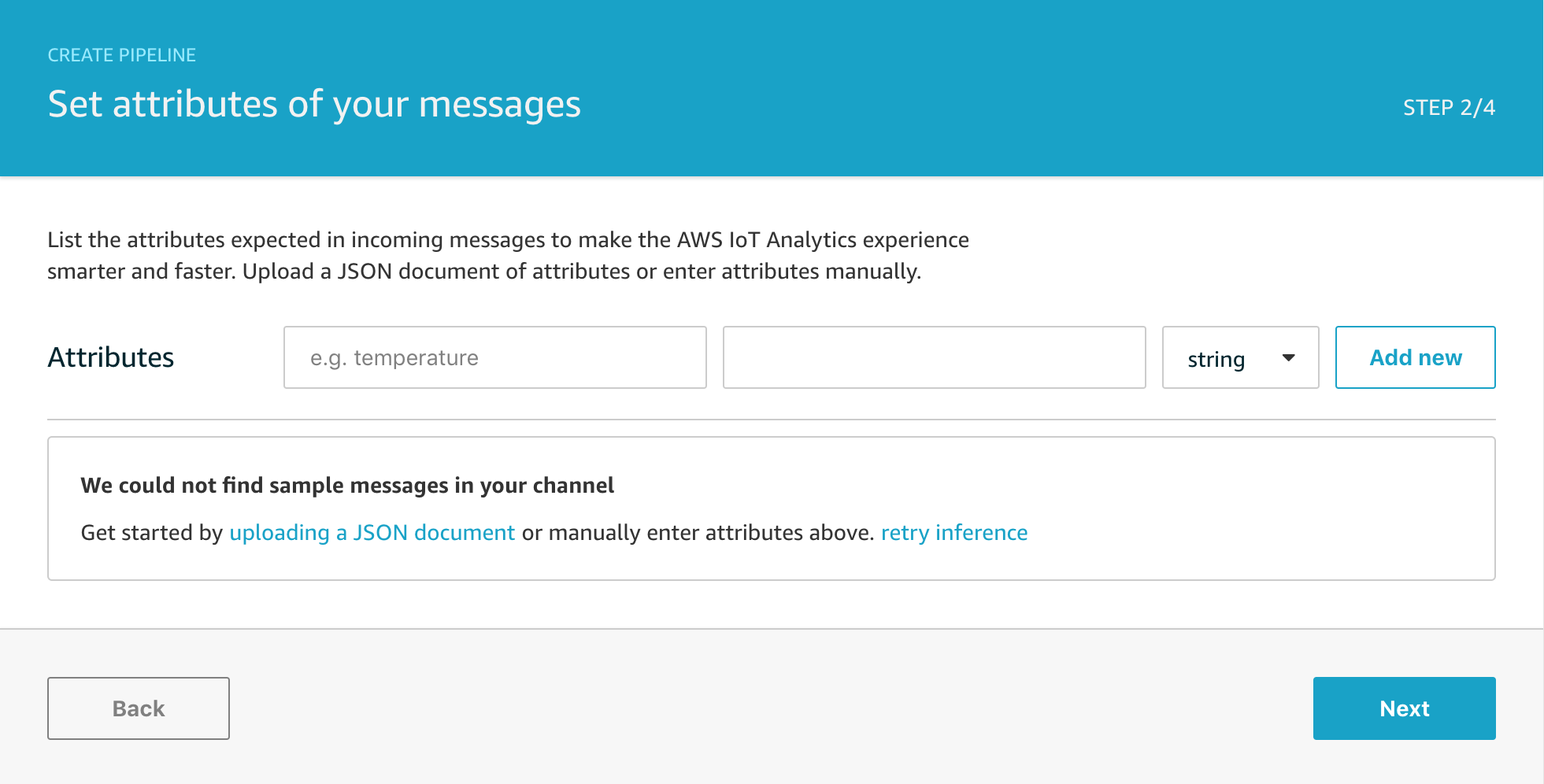
STEP TWO
On this screen, the console will attempt to find any existing messages in the channel and show you a sample of attributes that have been found. This helper can be useful for some of the later activity steps, but it’s completely optional and I generally just click through with Next to get straight to the next step.
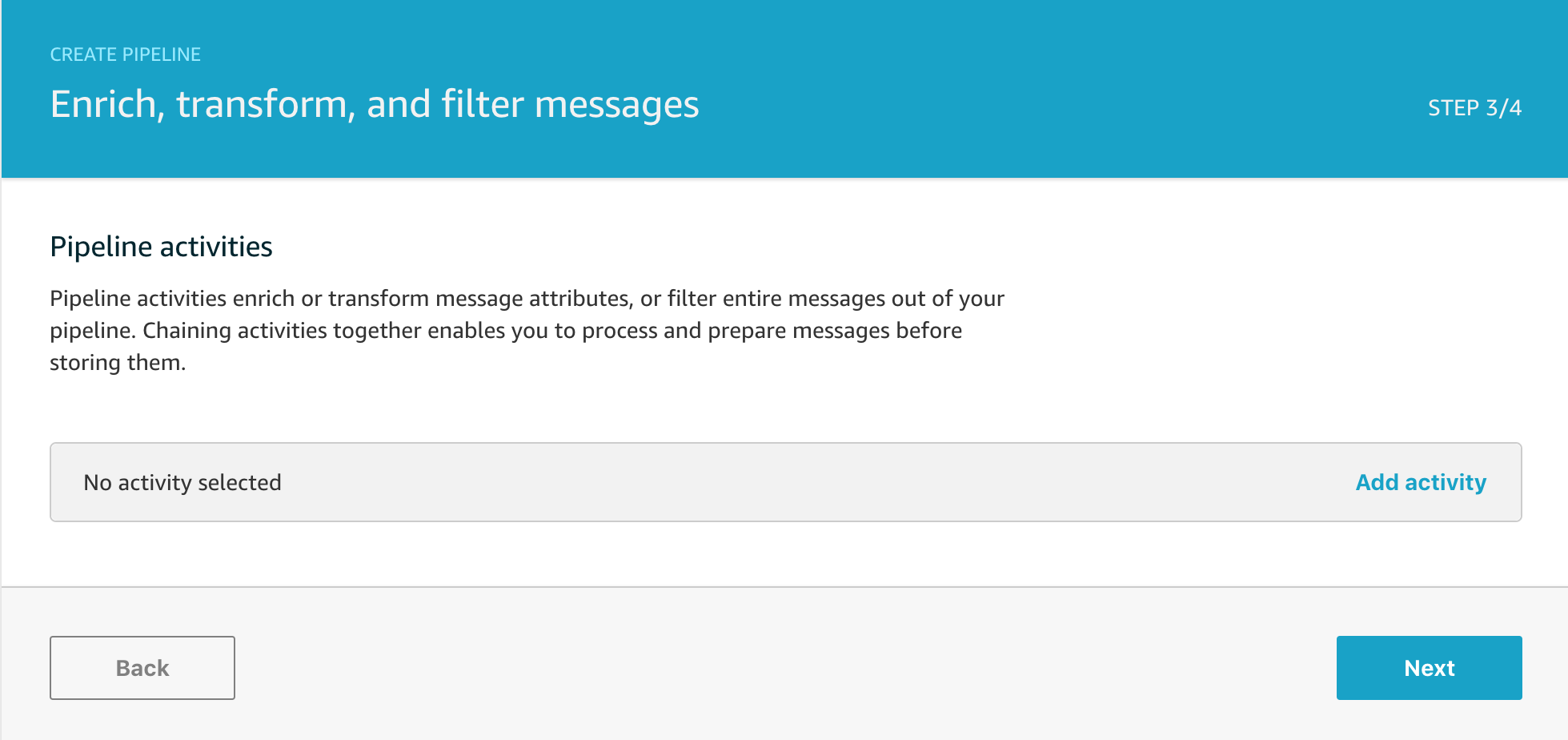
STEP THREE
On this screen you can configure any pipeline activities to transform your messages. I typically go back and do that later if I need to and find it faster to just click on Next to get straight to the final stage. If you already know exactly what you want to do though, you can add various processing activities for your data preparation stage here and we’ll discuss the activities in more detail another time.
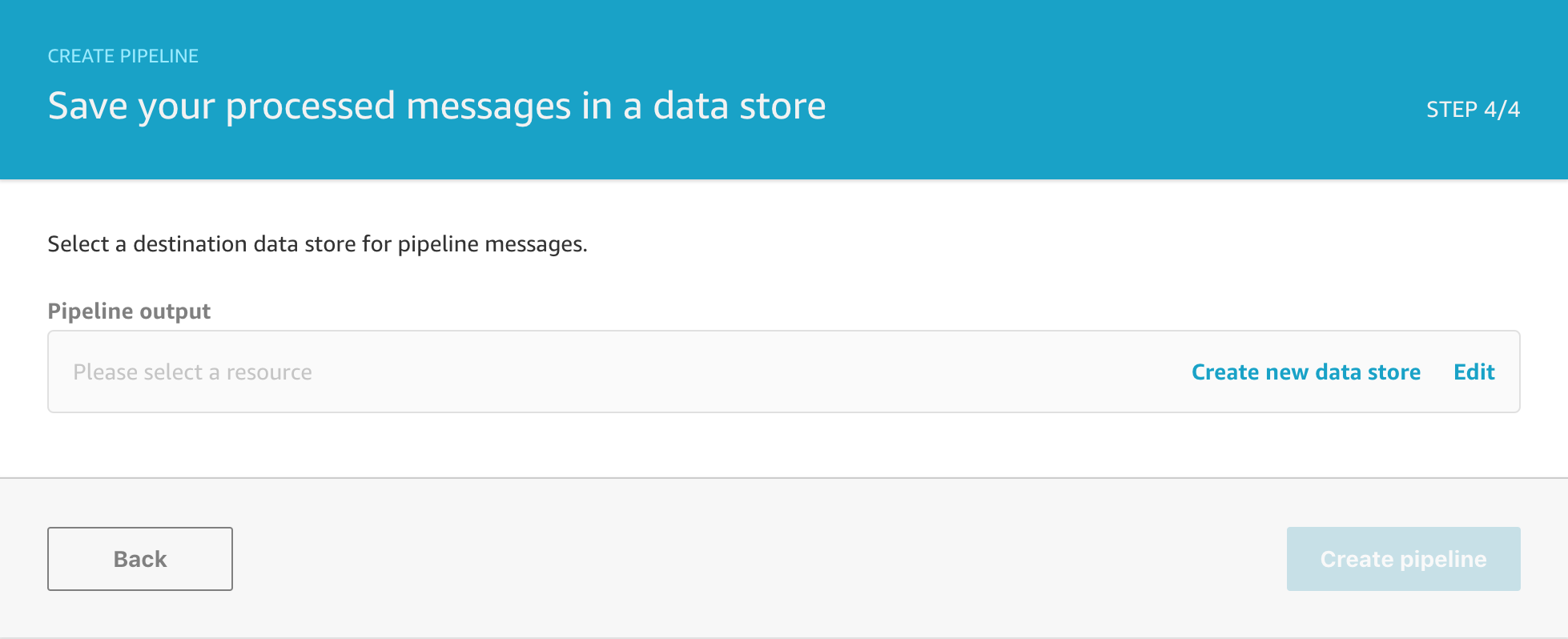
STEP FOUR
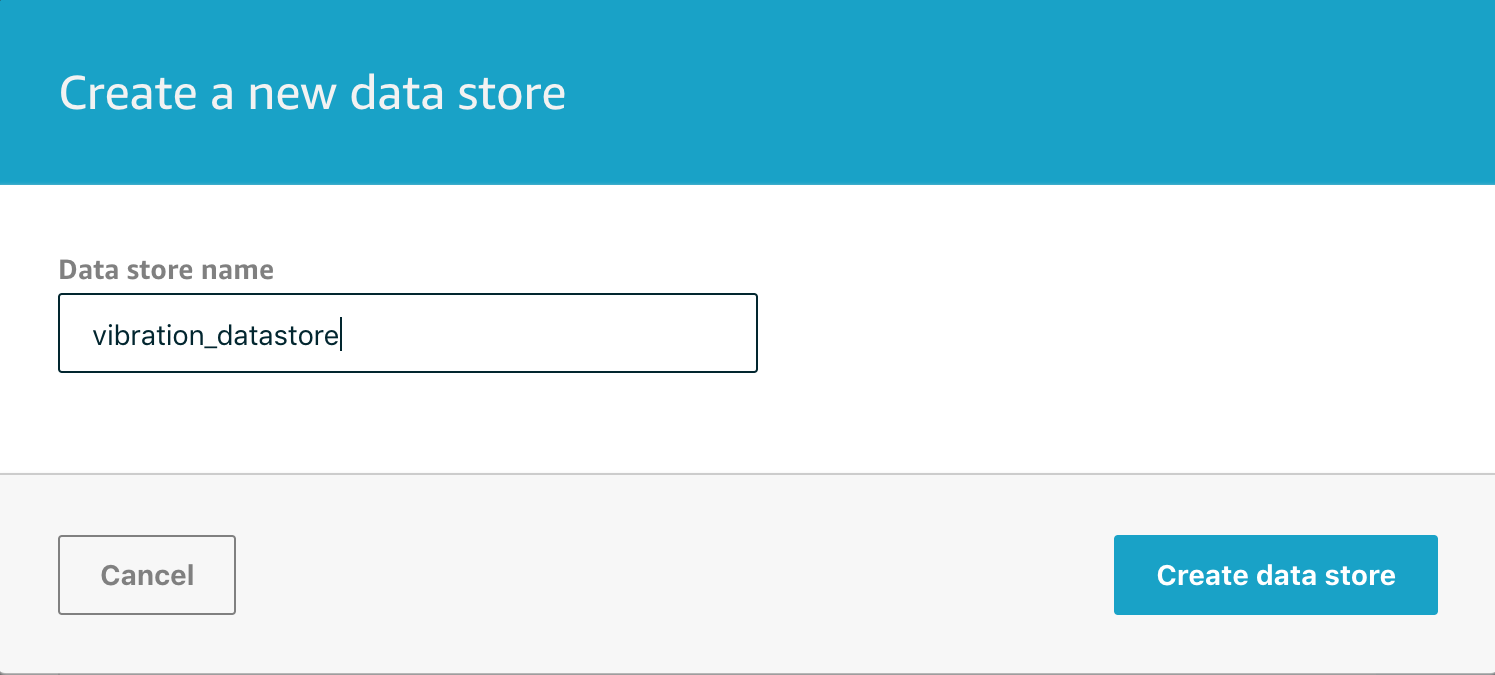
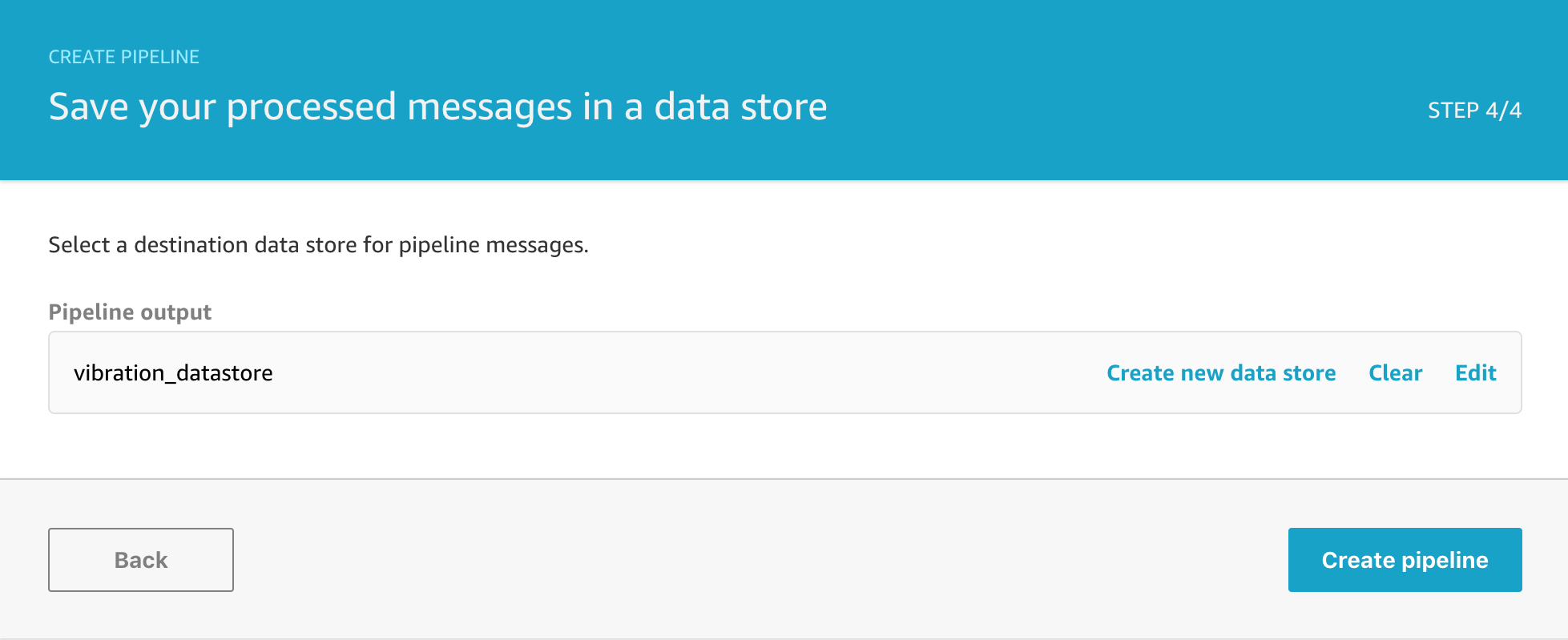
A Pipeline need to be connected to a Data store in order to process any messages and so this final step requires you to select an existing data store if you have one, or create a new data store if you need to. We don’t have any data stores yet so we will click on create a new data store to finish setting that up.
Give your data store a sensible name for this project as we’ll be needing to refer to it later on.
Clicking on Create data store will create the store for you and take you to the final screen in the Create Pipeline flow.
Finally, after clicking on Create pipeline, we’ll see that everything is setup and the pipeline is complete.
In conclusion, we’ve seen in part one and part two how to create a Channel to receive IoT messages from AWS IoT Core via Rules and how to create a processing Pipeline to connect the Channel to a Data store. Any messages we’re now sending on the MQTT topics we’re listening to will now be stored in the Data store where we can run analysis on them later – but that’s for a future topic.
I have a new IoT project at home to figure out if I can do some frequency analysis on the vibrations coming from our furnace motor to identify possible future failure once I’ve replaced the belt between the motor and the blower fan. I’m going to send the data to IoT Analytics so let’s use this as an example of how to get started.
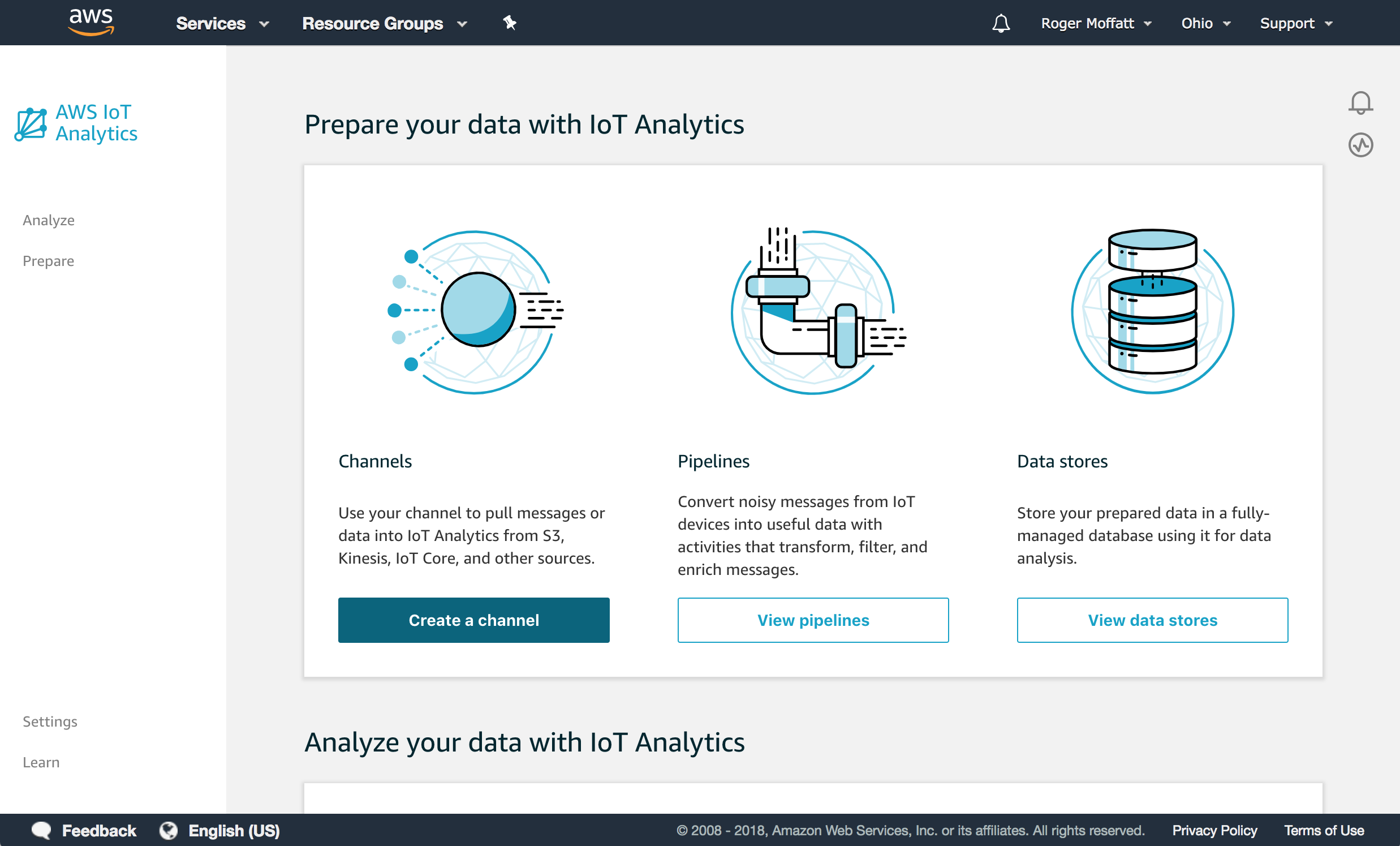
LAUNCH THE IOT ANALYTICS CONSOLE
Head over to the AWS Console and find IoT Analytics either by searching in the services list or scroll down and you’ll find a collection of IoT solutions grouped together on the right.
If you’re new to IoT Analytics, you’ll see a first time user experience screen that looks like this.
STEP ONE
Create a Channel to receive your messages. You can put messages into a Channel either by using an IoT Rule to send messages arriving to the AWS IoT gateway to an IoT Analytics Channel or you can send data directly using the batch-put-message API if your workflow supports that instead.
So let’s go ahead and click on Create a channel and give our channel an identifier we will use to refer to it later. As this project is all about vibration data, I’ll just call it vibration_channel. Note that you can’t change the identifier of a channel later on but you can tag the resource and use the tags to group and organise your channels and other resources once you start to have a lot of them.
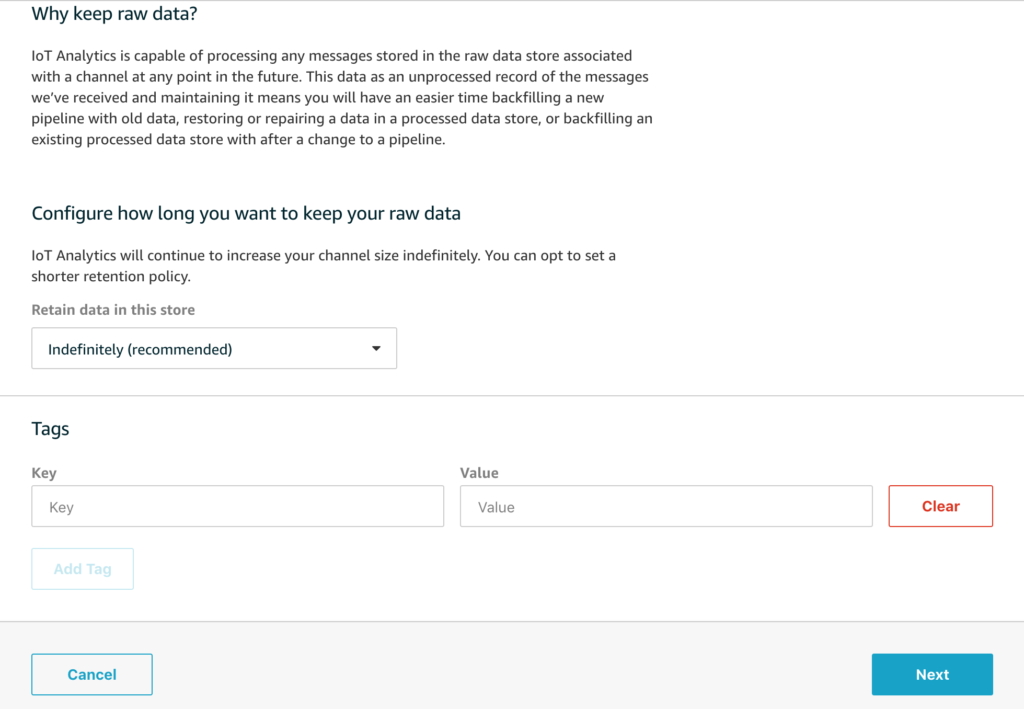
Now scroll down and click on NEXT. We will use the default data-retention period for our raw data which means that we will, in addition to the processed data that you can query, keep the original raw data in case we want to re-process it at a later date. This is one of the more advanced use cases for IoT Analytics and for now we will just proceed with the default settings.
STEP TWO
After clicking Next, we’ll be on the final screen in the Channel creation flow which looks like this.
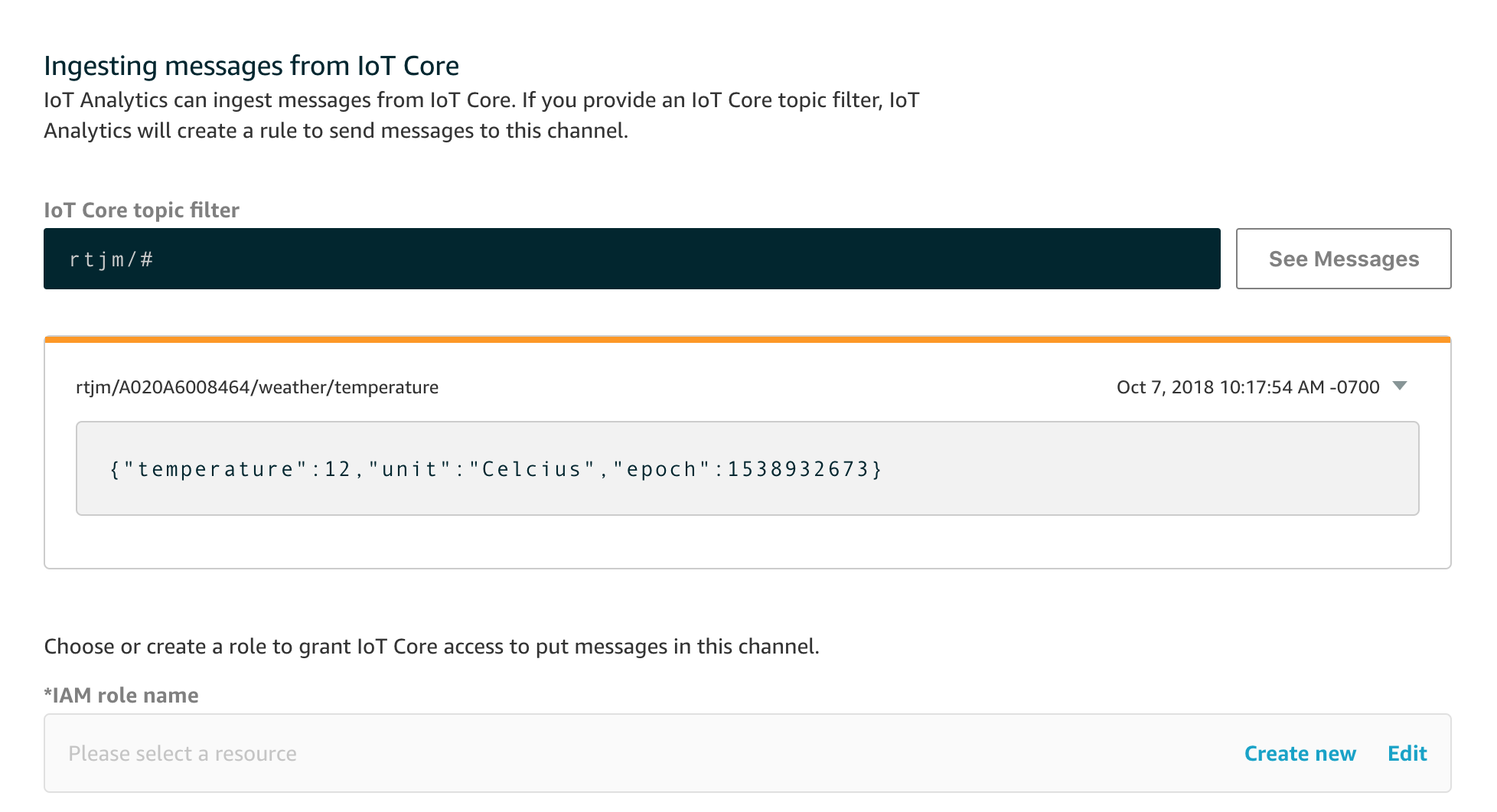
It’s important to say that you can simply go straight to clicking on Create Channel at this point, especially if you are using batch-put-message to send your data. As a convenience however, if you are sending messages to IoT Core, you can type a topic filter and IoT Analytics will create a Rule in IoT Core for you. You can even see the messages coming in live to that MQTT topic to check that you’re listening to the right topic or to have a look at the shape of the messages.
Let’s try that first and enter a topic and click on See Messages.
You’ll see I’ve used a wildcard topic filter in this case so the first message I’ve received is nothing to do with this particular project, but you get the idea.
STEP THREE
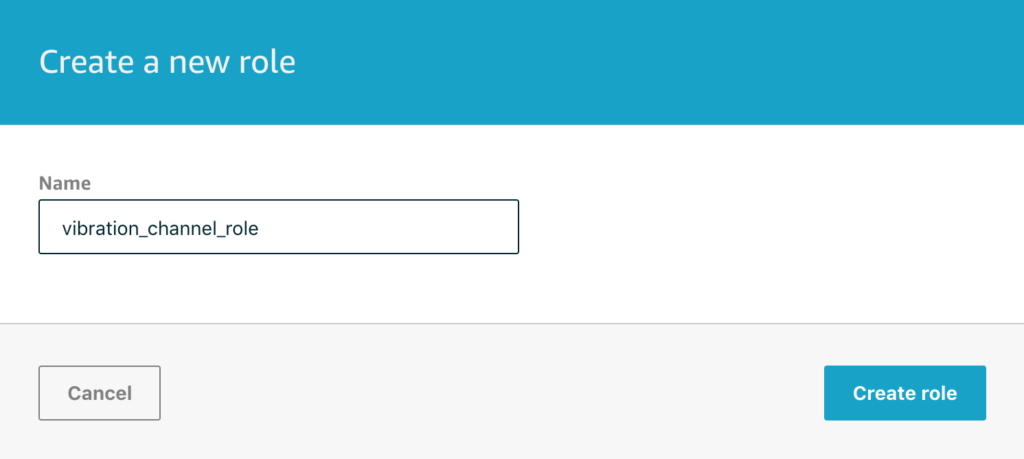
The next thing to point out is super important though. You’ll see that you need to choose or create a role to grant IoT Core the permissions needed to put messages into your channel. Typically I will use create new role here, but you need to be aware that the role that is created is scoped down to just this individual channel. This is important because you might be tempted to re-use this role for future channels – but this will not work as the channels are different. Of course one way around this is to use the IAM console to create a role scoped to any of your channels for example, but that’s for another day.
For this example, I’ll create a new role and then click on Create Channel to complete the process. This will take us back to the Channels page which lists all the Channels we have so far.
Let’s recap what we’ve done so far
We’ve created a channel called vibration_channel to collect our data.
We’ve created a new IAM role to grant IoT Core permissions to send data to the channel.
By creating a topic filter, we’ve automatically created a Rule in IoT Core which will route messages matching the filter to our newly created Channel.
Note that if you were using the AWS CLI or SDK to create the channel, the Rule is not created for you – this is assistance that is only provided by the console (but of course it’s easy to setup the Rule with the CLI or SDK as well).
We’re now ready to send data, but we’ll pick that up in part two.