
IoT devices send a wide range of message shapes and sizes, and for my own experiments, I typically send a different type of message for each sensor. So for example;
Cloud Sensor Message
{
"ambient": 9.649988,
"object": -2.509985,
"unit": "Celcius",
"epoch": 1538896592,
"status": {
"uptime": 88,
"heap": 15488,
"unit": "minute",
"rssi": -71
}
}
Temperature Sensor Message
{
"temperature": 10,
"unit": "Celcius",
"epoch": 1538896611
}
GPS Location Message
{
"time": "20181007T071731Z",
"kph": 0.01852,
"alt": 140.1,
"satellites": 11,
"hdop": 75,
"pos": [
"47.64",
"-122.36"
],
"age": 379,
"chk_f": 9,
"chk_s": 46175,
"fix": 10735
}
I have maybe 20-30 different messages in my small home automation setup and I’d like the freedom to be able to create new message formats without having to worry about how to store all this data for later analysis, so one of the first questions that arises is where should I store all this data?
A natural destination for any IOT device data is the new IoT Analytics service that was launched by AWS back in April at the world’s largest industrial technology trade fair “Hannover Messe”. IoT Analytics has several features that make the collection and later analysis of connected device data easy;
Flexible retention periods. Keep all your data for a week, a month or any period that you require, including of course unlimited retention. Aside from helping reduce costs by automatically removing old and non longer needed data, this also helps keep query performance higher by lowering the overall amount of data being scanned.
Zero schema configuration required. You don’t need to specify any partition keys or column names or tell IoT Analytics anything about your message schema. Just send the data and it will be stored and made available for query. I like this because it makes it super easy to get up and running.
Preprocess message data before storage. IoT Analytics has a Pipeline that connects the incoming messages from a Channel to the Datastore – your data lake of connected device data. This gives me a data preparation step where I can enrich or transform the message according to my requirements. For example I might want to enrich the message with data from the IoT device shadow or add information from the IoT device registry. I might want to convert a measurement in fahrenheit to celcius or even call out to an external service to get some additional data about the device to add to the message. There are some pretty cool things you can do with the data preparation stage and I’ll write more about those another time.
Ability to write standard SQL queries against your data. I call this out in particular because prior to the release of AWS IoT Analytics, I was using AWS ElasticSearch as my data repository. This had similar ease of use characteristics regarding schema configuration (not quite zero touch, but not particularly onerous either) and was certainly useful for visual analysis and deep diving with Kibana, but ES has it’s own query language based on Lucene and this makes decades of familiarity with SQL obsolete and having to learn how to query from the beginning was a learning curve that I sometimes found frustrating.
Recurring scheduled queries. One of my use cases concerns looking at historic and future weather data to determine when to turn on an irrigation system and for how long. I want to execute this analysis every evening to configure the watering for the next day – a perfect fit for a scheduled query that runs every day. Another use case I have is that of analysing upper atmosphere clarity to see if my telescope should continue to execute its observing program – a great fit for analysis that is scheduled to run every 15 minutes.
I love being able to automate my analysis like this without having to write a single line of code. This definitely makes my life easier when I’m wearing my data scientist hat.
And, saving the best for last …
Automated execution of Jupyter Notebooks for fully hands-off analysis workloads. For me, this is the real engine within IoT Analytics that makes it so flexible and capable. Not only can I use the notebook to perform deeper statistical analysis or train an ML scenario, or draw complex graphs and charts, but because I have the full power of the AWS SDK at my fingertips, I can do anything you can think of doing with all the tools that puts at your disposal. One simple use case I solve with this approach is to configure AWS CloudWatch Event Rules to schedule when water should be turned on and off and I’ll write more about this in some detail another time.
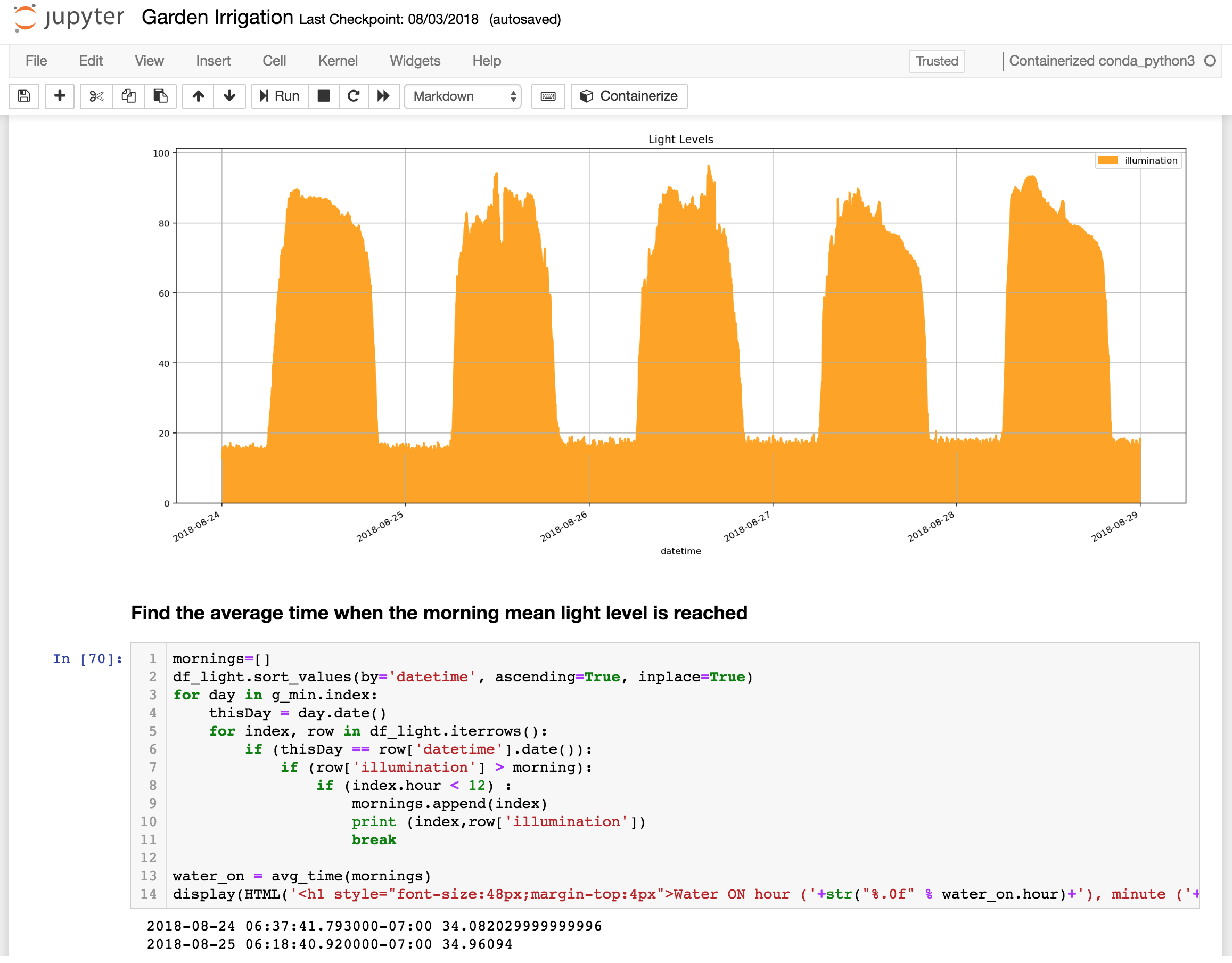
In conclusion, the ease of sending any data in, the ability to query the data on an automated schedule and the power of the analysis available has enabled me to focus more on the business problems I’m trying to solve. For every new project I’m dreaming up (I’m an inveterate tinkerer remember), I just create a new IoT Analytics Channel->Pipeline->Datastore and that becomes the home for all the device data I’m sending.